This blog post is postmortem of my infrastructure that was attacked on Sunday by Argentinian attacker and died because of DDoS. I will share with you all actions that I took in order to bring back stability of services.
Summary
Attack has started : 19 June 2016 at 3:20PM UTC
Attack has ended : 19 June 2016 at 4:10PM UTC
Users affected : 30-40 users
Extra cost due to attack : less than 2$
Existing Infrastructure
Let me give you a brief overview of existing infrastructure of Helbreath Poland.
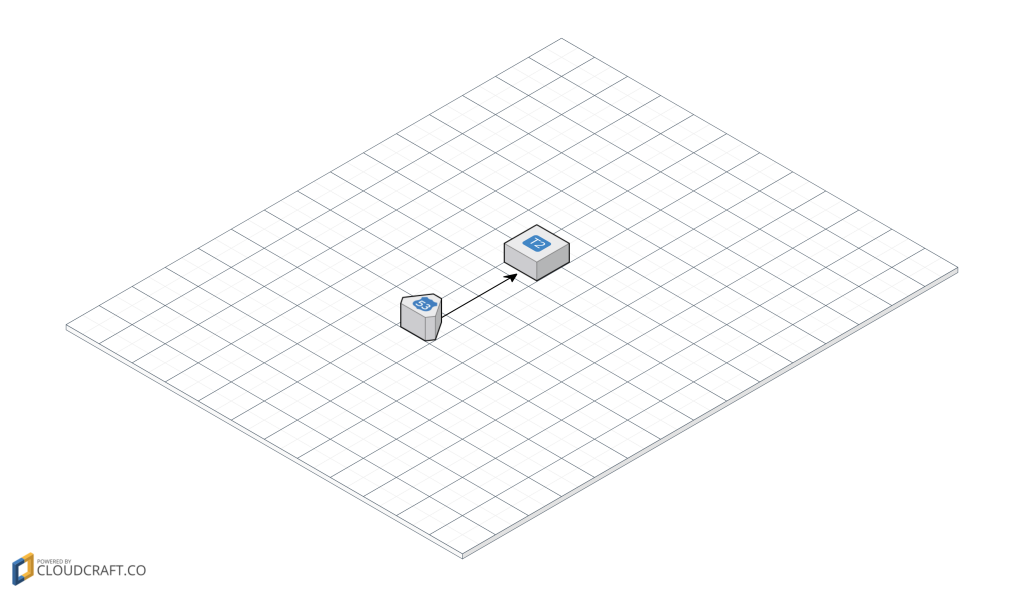
On the image above you can see two components that create my infrastructure, it is Route53 and one small t2 EC2 instance.
Let’s agree on something, it is not difficult and “big” infrastructure, but for this purpose it works perfectly, right now the server has 30-40 people playing every second, possibly with this VM we can go up with 100 ? 150 more people ? But for a now it is fine!
DDoS what is that !?
In the simplest terms, DDoS is a type of attack that sends a lot of data from lots of places (computers), often you can say that it is distributed attack because you can use computers from a different part of the world to attack somebody infrastructure.
Aggressors send a lot of data so that your infrastructure can’t handle so many incoming packages, and eventually will stop working or access will be very limited. This type of attack doesn’t require really big knowledge, everyone who has access to the internet can prepare that kind of attack. Deeper explanation you can find at Wikipedia.
In our case, they were attacking two ports: 321, 1 and 3007 over TCP.
Full story
The calm before the storm
I knew that something will happen because there was a player that log in to our server and threat to us that he is going to destroy the server. Well in after 5 minutes, people start getting lag, and more lags, then a lot of them got disconnected from the server.
So it begins, my actions
The server was basically killed, VM don’t respond.
As a said earlier, people got lags, disconnected. I started doing some investigation and I tried to log into my VM but…yeah, I couldn’t even do that. RDP wasn’t responding.
Decided to switch off all incoming traffic, and allow only to my IP.
I decided to switch off all incoming traffic, which means that VM is taken out from public availability. That way I cut off all incoming good and “dirty” connections.
I have done that by changing a rule in a security group, as on the image below. First rule, All TCP, Anywhere has been removed.
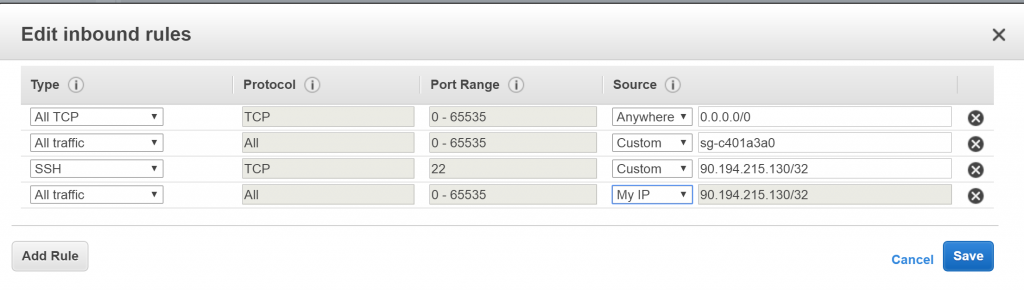
While all traffic is disallowed except my computer. I can log in and maintain a VM. Which means do backups check logs what happened, look for attacker IP address.
Gradually open traffic but it seems that there is still an issue.
Next decision that I have taken was to start gradually allowing incoming external traffic to my infrastructure.
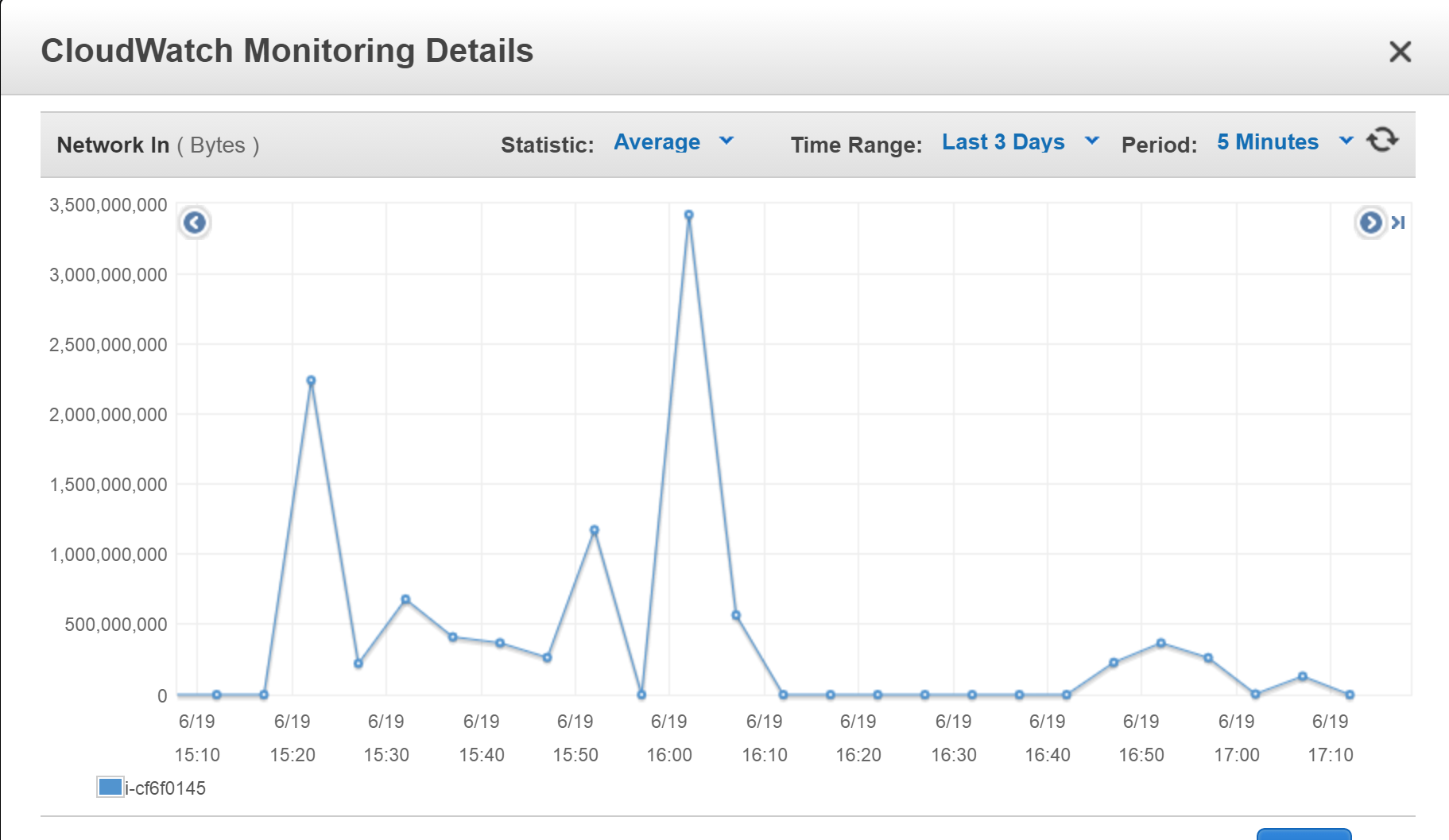
But as you can see below there was second hit even greater. Between 1530 and 1600 was quite calm, but then when I allowed around 16:00 was a big bang.
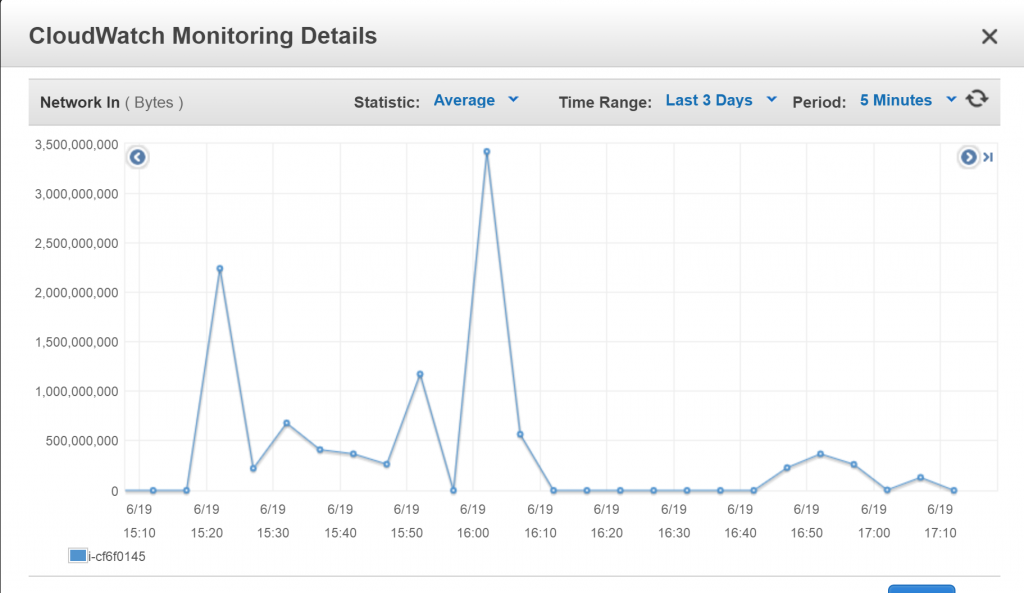
Again, repeat first step switched off everything and let’s wait…
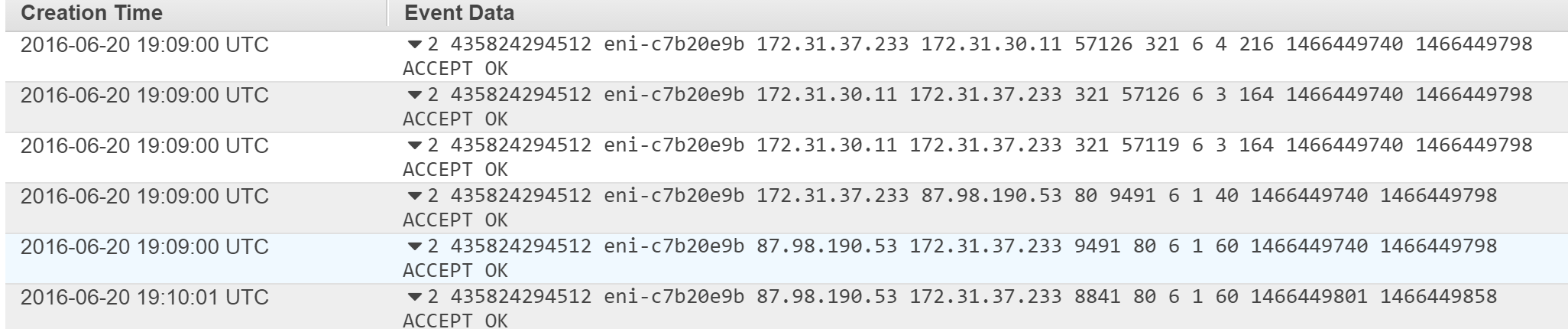
Check IPAddress of attackers
In a meantime, I was looking for IP address/es of attackers, and I found that attacker was from Argentina.
Add entry to ACL with IPAddress, decided to block attacker their entire subnet
To prevent and block any dirty connection, I have updated ACL that manage and filter out any incoming and outcoming traffic. I decided that the safest option is to block their whole subnet.

Again start letting incoming traffic to infrastructure.
At the end around 16:05 I started once again to letting people into the server.
You can see on the image below incoming network. From about 16:05-16:10 send data is on a fairly OK level if you compare with what was 20 minutes before.
People can log in and they don’t have any problems with the game.
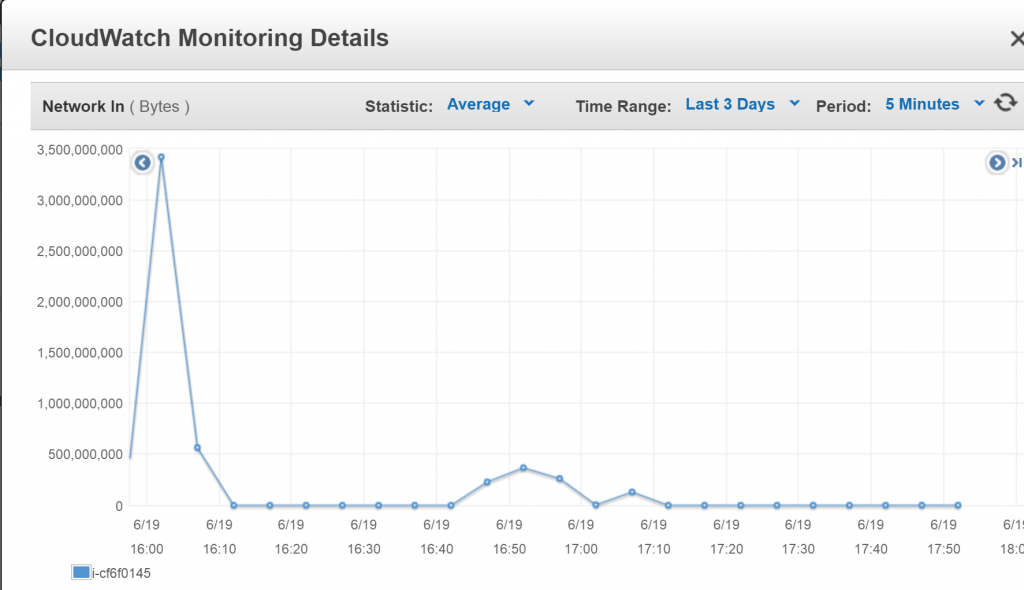
Problem solved, what next ?
That was my quick story what happened to me on Sunday afternoon. Problem solved but what about further actions to prevent, or maybe create a failover plan, that can at least allow people to play ?
Introduce Load Balancer
First of all, what I have to do is to introduce a load balancer (ELB), even for this one VM. In the future if I will notice that attack is incoming I can immediately spin up fresh VM and redirect every player to this box. In a meantime, I have some extra time to deal with attackers.
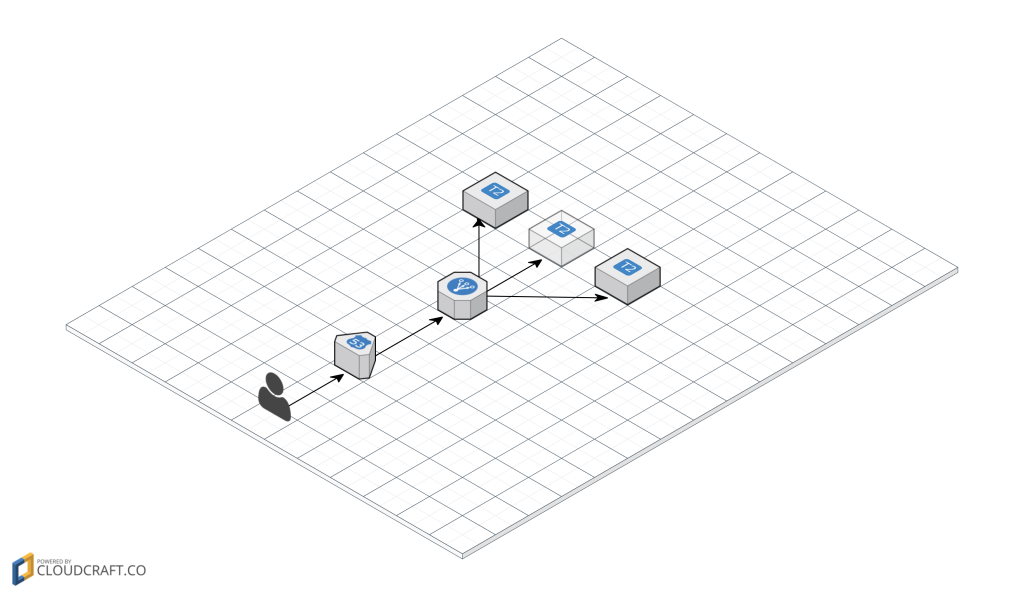
Let’s imagine that attack is incoming, and a middle box is affected, so I immediately spin up two VM and fire up services on this boxes.
Because players connect by DNS, and it will be a stream for ELB, they will be automatically redirected to healthy instances. Of course, this way won’t help if an attack will be really, really serious and they will attack directly DNS
Monitor incoming connection to get a better overview.
This is very important! My infrastructure didn’t have this at the point of attack. If this attacker didn’t log into the game and threat to us. I wouldn’t know explicit his IP Address. Which could complicate things and probably it would take me much more time to solve this issue.
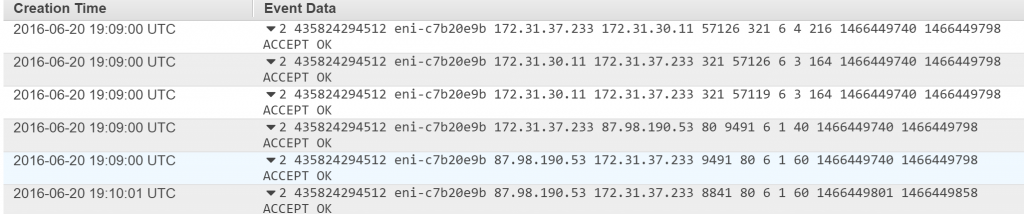
With help comes Flow Logs in AWS for your VPC. This monitor and log all IP addresses that are connected to your infrastructure. That way if they will attack again, from different subnet I can get their IP addresses from logs, then block traffic of this subnet to my infrastructure.
Set alarms on the usage of VM resources.
This part is also very important and it is going to play nicely with previous steps, so on AWS you can set up alarms if a specific resource is going to beyond of a certain threshold.

In my case, I have created an alarm for data send to my VM by the external world. The alarm will go off when there will be a spike to of incoming data greater than 1GB a minute then it will send me a notification to an email. That way I can be aware of the possible attack or big popularity of my server 😀 and jump into action
Closing words
To sum up, that was a really amazing experience even if some players were affected and I was really pissed off, but I treat this as a lesson because I have learnt a lot of additional functionalities on AWS, and general ops approach this problem.